Maksim Déry
DQN Plays Breakout est un projet d’intelligence artificielle appliquée au jeu vidéo, dans lequel un agent apprend de façon autonome à jouer à Breakout à l’aide de l’apprentissage par renforcement profond. L’objectif du projet est de permettre à une intelligence artificielle de prendre des décisions en temps réel à partir de l’image du jeu, sans script prédéfini ni règles codées manuellement.
Le projet met en œuvre un modèle de type Deep Q-Network (DQN), popularisé par DeepMind, afin d’entraîner un agent à maximiser son score au fil des parties. L’agent observe l’environnement, analyse les images successives du jeu, puis apprend progressivement quelles actions sont les plus efficaces pour garder la balle en jeu et détruire les briques.
Les principaux objectifs du projet étaient les suivants :
- entraîner un agent capable d’apprendre à jouer sans intervention humaine ;
- reproduire une approche classique du Deep Reinforcement Learning ;
- mettre en place un pipeline complet d’entraînement, de sauvegarde et de reprise ;
- optimiser l’exécution pour fonctionner même sur une machine sans GPU récent ;
- permettre une visualisation concrète des performances de l’agent en jeu.
Apprentissage de l’agent
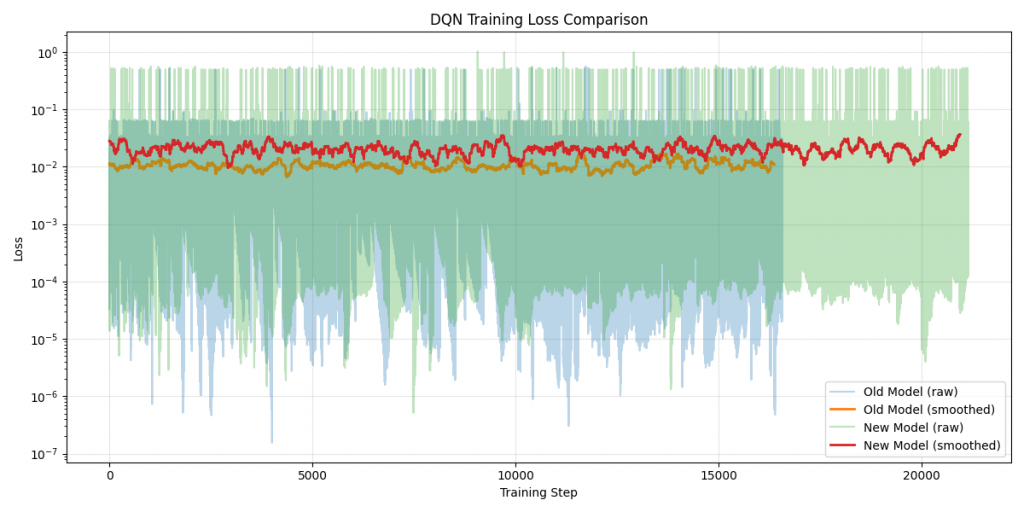
Le cœur du projet repose sur un système d’apprentissage par renforcement, où l’agent interagit directement avec l’environnement du jeu. À chaque étape, il choisit une action, reçoit une récompense, puis ajuste progressivement son comportement en fonction des résultats obtenus.
L’approche utilisée permet :
- d’apprendre à partir de l’expérience accumulée en jeu ;
- d’exploiter une mémoire de rejouabilité (replay buffer) pour stabiliser l’entraînement ;
- d’utiliser une stratégie epsilon-greedy afin d’alterner entre exploration et exploitation ;
- de mettre à jour un réseau cible séparé pour limiter l’instabilité de l’apprentissage ;
- de sauvegarder automatiquement la progression grâce à un système de checkpoints.
Cette structure rend l’entraînement plus robuste et permet de reprendre le travail sans perdre les progrès déjà effectués.
Traitement des données visuelles
Comme l’agent n’a pas accès à une représentation abstraite du jeu, il doit apprendre à partir de l’image brute. Une phase de prétraitement a donc été mise en place pour réduire la complexité des données tout en conservant l’information essentielle.
Le pipeline visuel comprend :
- conversion des images en niveaux de gris ;
- redimensionnement des frames en 84 x 84 pixels ;
- empilement de 4 frames consécutives pour conserver l’information sur le mouvement ;
- normalisation implicite des valeurs lors du passage dans le réseau de neurones ;
- réduction du coût de calcul afin d’accélérer l’entraînement.
Cette approche permet à l’agent de mieux percevoir la trajectoire de la balle et la dynamique générale de la partie.
Description technique
Le choix technique principal du projet est l’utilisation d’un réseau de neurones convolutif inspiré de l’architecture DeepMind, combiné à une logique de DQN classique. Le système est conçu pour être modulaire, lisible et facilement extensible.
Le projet comprend notamment :
- un réseau convolutif chargé d’extraire les caractéristiques visuelles du jeu ;
- une mémoire d’expérience pour stocker les transitions vécues par l’agent ;
- un système de réseau principal et de réseau cible ;
- une logique de sauvegarde automatique du modèle et de l’état d’entraînement ;
- un mode d’exécution permettant de rejouer les parties du modèle entraîné avec rendu OpenCV.
Un autre aspect intéressant du projet est l’attention portée à la compatibilité matérielle. Le code détecte automatiquement si un GPU CUDA récent est disponible, puis bascule vers le CPU lorsque le matériel ne permet pas une exécution optimale. Cette décision rend le projet plus portable et plus réaliste dans un contexte de développement personnel.
Résultat et intérêt du projet
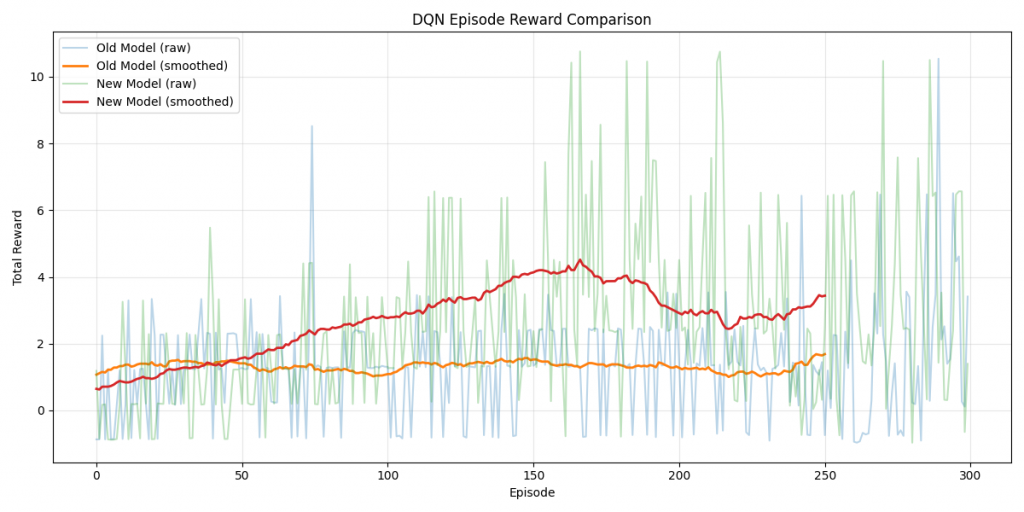
Ce projet démontre concrètement comment une intelligence artificielle peut apprendre un comportement à partir de simples observations visuelles et d’un système de récompense. Il illustre aussi plusieurs concepts importants en apprentissage machine, notamment :
- l’apprentissage par renforcement ;
- les réseaux de neurones convolutifs ;
- la gestion de l’exploration ;
- la stabilisation de l’entraînement par réseau cible ;
- la persistance des modèles par checkpoints.
Au-delà de l’aspect expérimental, ce projet m’a permis de consolider ma compréhension des systèmes intelligents appliqués au jeu vidéo, tout en travaillant sur des enjeux réels d’optimisation, de performance et de robustesse.
Technologies utilisées
- Langage : Python
- Librairies IA : PyTorch, NumPy
- Environnement : Gymnasium, ALE
- Traitement d’image : OpenCV
- Type d’IA : Deep Reinforcement Learning
- Approche : Deep Q-Network (DQN)
- Jeu utilisé : Breakout (Atari)