Dans le cadre du IA Hack des 28 et 29 mars 2026, notre équipe a développé une solution d’intelligence artificielle capable d’analyser des enregistrements audio marins afin de classifier différentes espèces et de détecter des appels dans des fichiers plus longs. Ce projet nous a permis d’obtenir la deuxième place du hackathon.
L’objectif du projet était de concevoir un pipeline complet capable de traiter des extraits audio, d’en extraire des caractéristiques pertinentes, d’entraîner plusieurs modèles de classification, puis de présenter les résultats dans une interface simple et concrète. Le système a été pensé en deux volets complémentaires : une première partie consacrée à la classification d’extraits audio courts, puis une seconde dédiée à la détection sur des enregistrements plus longs.
Objectifs du projet
Les principaux objectifs du projet étaient les suivants :
- classifier automatiquement des extraits sonores associés à différentes espèces marines ;
- détecter la présence d’appels dans des enregistrements audio plus longs ;
- comparer plusieurs approches de classification afin de retenir le meilleur modèle ;
- concevoir une solution complète allant de l’entraînement jusqu’à la visualisation des résultats ;
- produire une démonstration claire et exploitable dans un contexte de présentation.
Ce travail nous a permis de construire une chaîne de traitement cohérente, allant du prétraitement audio jusqu’à l’interface de démonstration.
Classification d’extraits audio
La première partie du projet repose sur la classification d’extraits audio courts. Pour chaque fichier, plusieurs caractéristiques ont été extraites à l’aide de bibliothèques spécialisées en traitement du signal. Parmi celles-ci, on retrouve notamment les MFCC, le spectral centroid, le spectral bandwidth, le zero crossing rate, le RMS ainsi que les chromas.
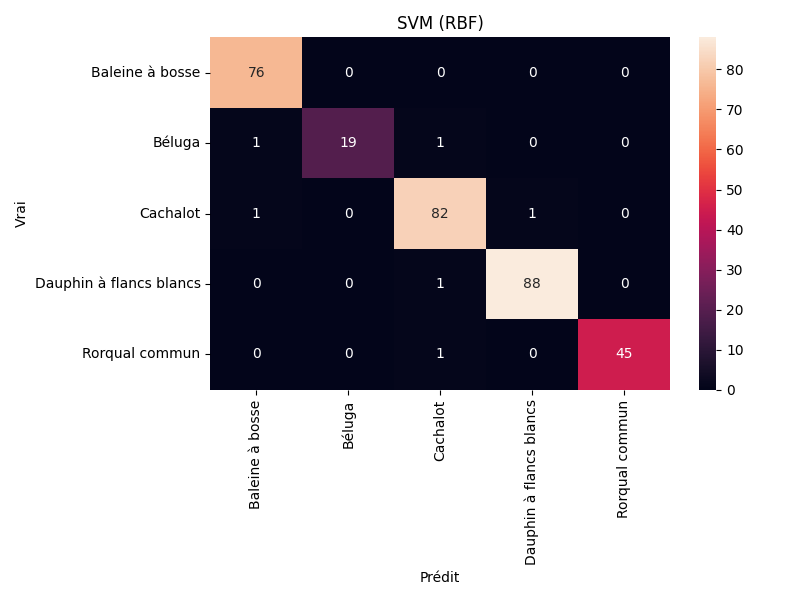
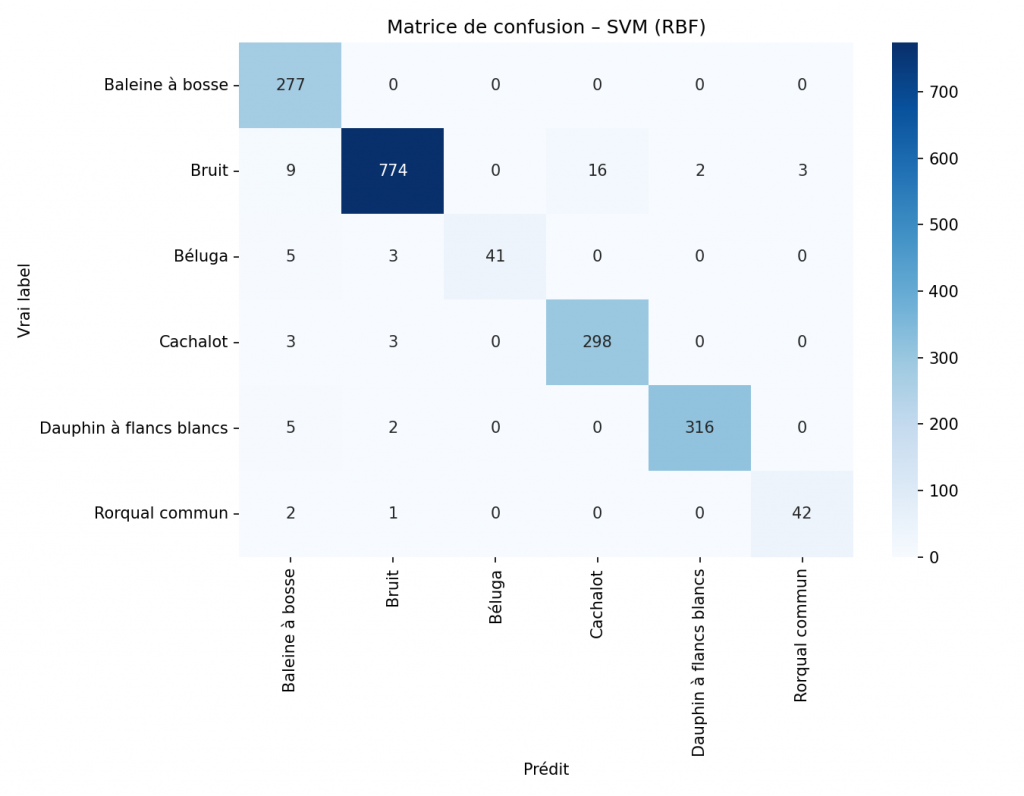
Ces caractéristiques permettent de résumer le contenu fréquentiel, l’énergie et la texture du signal sonore sous une forme exploitable par des modèles de machine learning. Plusieurs approches ont ensuite été comparées, notamment Random Forest, SVM, KNN et Gradient Boosting. Chaque modèle a été évalué afin d’identifier celui qui offrait les meilleurs résultats sur les données de test.
Détection dans les enregistrements longs
La seconde partie du projet visait un problème plus réaliste : analyser un long enregistrement audio et identifier les segments contenant des appels. Pour cela, nous avons mis en place une approche par fenêtres glissantes. Le signal est découpé en segments successifs, chacun étant analysé individuellement avant d’être classifié.
Cette étape ajoute une dimension temporelle importante au projet. Au lieu de simplement attribuer une classe à un fichier complet, le système peut localiser dans le temps les événements sonores pertinents. Cela permet de produire des résultats plus utiles dans un contexte réel d’analyse acoustique.
Pour rendre cette détection plus robuste, nous avons également utilisé des caractéristiques supplémentaires comme les dérivées temporelles des MFCC, le spectral rolloff, le spectral contrast et d’autres mesures spectrales. Des règles de filtrage ont ensuite été appliquées afin d’éliminer certaines prédictions peu fiables et de fusionner les détections rapprochées.
Interface de démonstration
Afin de rendre le projet plus concret et plus facile à présenter, nous avons développé une interface avec Streamlit. Cette interface permet de charger des fichiers audio, de lancer des prédictions, d’afficher les classes détectées et de visualiser les résultats sous une forme simple à interpréter.
L’application inclut également des éléments visuels comme des matrices de confusion, des tableaux de détections et une représentation temporelle des appels détectés dans les fichiers longs. Cet aspect a été particulièrement utile dans le cadre du hackathon, car il permettait de démontrer rapidement et clairement le fonctionnement de notre solution.
Description technique
Le projet repose sur une architecture modulaire séparant clairement l’entraînement, l’évaluation, la détection et la visualisation. Cette organisation rend le système plus lisible, plus maintenable et plus facile à faire évoluer.
Le pipeline comprend notamment :
- une étape d’extraction de caractéristiques audio ;
- une comparaison de plusieurs modèles de classification supervisée ;
- une logique de détection par fenêtres glissantes pour les fichiers longs ;
- un système de sauvegarde et de rechargement des modèles entraînés ;
- une interface web de démonstration indépendante de l’entraînement.
Cette structure montre bien qu’au-delà du modèle lui-même, le projet a été pensé comme une solution complète, allant du traitement des données jusqu’à la présentation du résultat final.
Résultat et intérêt du projet
Ce projet démontre qu’il est possible de construire, dans un temps limité, une solution cohérente d’intelligence artificielle appliquée à l’analyse audio. Il met en pratique plusieurs concepts importants, notamment le traitement du signal, l’extraction de caractéristiques, la classification supervisée, l’évaluation de modèles et la détection événementielle sur séries temporelles.
Le fait d’avoir obtenu la deuxième place lors de l’IA Hack des 28 et 29 mars 2026 vient confirmer la qualité du travail réalisé par notre équipe, autant sur le plan technique que sur celui de la démonstration. Pour ma part, ce projet m’a permis de consolider mes compétences en intelligence artificielle appliquée, tout en travaillant dans un contexte intensif, collaboratif et orienté résultats.
Technologies utilisées
- Langage : Python
- Traitement audio : Librosa, NumPy, Pandas
- Machine learning : scikit-learn
- Visualisation : Matplotlib, Seaborn
- Interface : Streamlit
- Modèles testés : SVM, Random Forest, KNN, Gradient Boosting
- Approche : classification audio supervisée et détection par fenêtres glissantes
Maksim Déry, Julien Otis